Les machines qui reconnaissent notre voix
On confond souvent reconnaissance de la parole et reconnaissance de la voix, mais ce sont deux notions différentes.
- Dans le premier cas, l’objectif est de comprendre ce qui est dit : ce sont les systèmes ASR, présentés dans le chapitre précédent.
- Dans le second cas, il s’agit de reconnaître une empreinte vocale afin d’identifier la personne qui parle.
Une expérience pratique
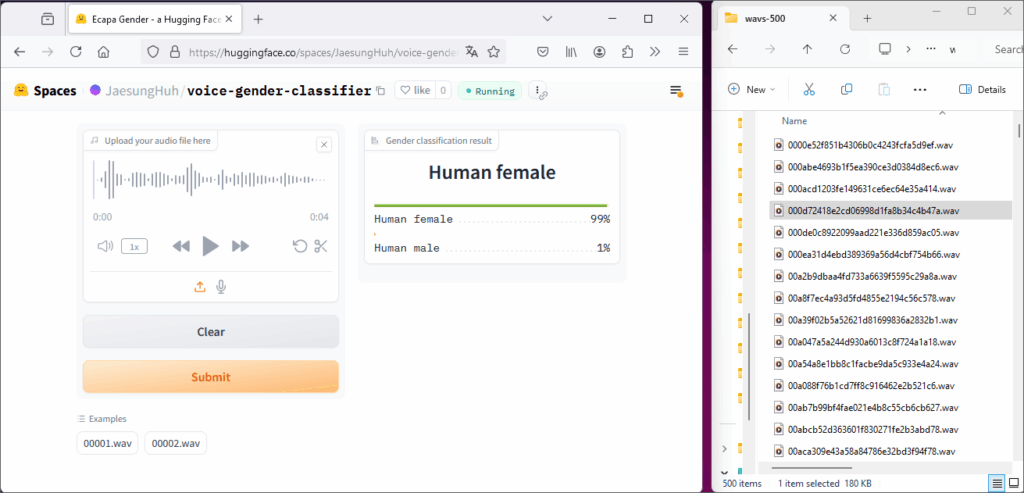
Lors de l’entraînement du modèle TTS avec la voix de Max Kuborn, je me suis heurté à un problème inattendu: il fallait distinguer les enregistrements masculins et féminins.
En effet, les métriques associées à la création du modèle luxembourgeois ne progressaient pas de façon cohérente. Après enquête, j’ai découvert que la base de données (environ 45.000 échantillons) contenait quelques centaines d’enregistrements d’une collaboratrice du ZLS. Une erreur de manipulation lors de l’assemblage par le ZLS avait provoqué ce mélange. Ni les noms des fichiers ni leurs dates n’aidaient à faire le tri. Une séparation manuelle, en écoutant chaque échantillon, aurait été irréaliste vu le volume.
J’ai donc demandé à ChatGPT de générer une application pour automatiser le tri. L’IA a produit un script Python qui analysait les fréquences sonores et l’intonation. Mais les résultats n’étaient pas assez fiables. Finalement, j’ai trouvé sur HuggingFace l’outil IA voice-gender-classifier, développé par Jaesung Huh. Avec un petit script Python, j’ai pu l’intégrer et utiliser cette application pour filtrer correctement la base. Après nettoyage, l’entraînement du modèle TTS s’est déroulé sans difficulté.
De la reconnaissance de genre à la diarisation
Depuis cet incident, survenu en juin 2024, de nouveaux outils de diarisation sont apparus. Ces systèmes ne se contentent plus de distinguer les voix masculines et féminines : ils répondent avec précision à la question clé de la diarisation :
👉 « Qui parle, et à quel moment ? »
Un système de diarisation combine généralement plusieurs étapes :
- Segmentation : découper l’audio en morceaux correspondant à une seule voix.
- Caractérisation : extraire des empreintes vocales (embeddings) qui résument les caractéristiques de la voix (timbre, hauteur, spectre).
- Clustering : regrouper les segments similaires pour déterminer combien de personnes parlent et attribuer chaque segment au bon locuteur.
- Étiquetage : associer chaque voix à une identité (par exemple Alice ou Bob), si un échantillon de référence est disponible.