Les machines qui reconnaissent notre parole
Les machines qui reconnaissent notre parole (ASR – Automatic Speech Recognition, respectivement STT = Speech to Text) comprennent ce que nous disons : elles convertissent la parole en texte.
Chacun a probablement déjà utilisé un assistant personnel pour dicter un message. Les plus connus sont :
- Siri (2011), d’Apple,
- Google Assistant (2012), sur smartphones Android,
- Cortana (2014), intégré aux systèmes Windows de Microsoft,
- Alexa (2014), développée par Amazon pour ses enceintes connectées,
- Bixby (2017), assistant vocal de Samsung.
Les pionniers
Ces outils modernes ont eu des prédécesseurs bien plus anciens :
- 1952 : Audrey, développé par les laboratoires Bell, ne reconnaissait que les chiffres de 0 à 9, et uniquement pour un locuteur spécifique.
- 1962 : à l’exposition universelle de Seattle, IBM présente Shoebox, capable de reconnaître en outre 16 mots liés aux opérations arithmétiques de base. Il est considéré comme l’un des ancêtres de la reconnaissance vocale interactive.
- 1976 : Harpy, développé à l’Université Carnegie Mellon (Pittsburgh), maîtrisait déjà un vocabulaire de 1000 mots. Il reposait sur les réseaux d’états finis, qui ont jeté les bases des modèles de Markov cachés (HMM). Les HMM ont dominé la recherche et les applications en reconnaissance vocale pendant plusieurs décennies, jusqu’à l’arrivée de l’apprentissage profond sur les réseaux neuronaux.
La révolution Dragon
En 1997, le logiciel Dragon NaturallySpeaking marque une véritable révolution : c’est le premier logiciel grand public de dictée vocale continue. Il est adopté massivement par les professionnels (médecins, avocats, secrétaires, etc.). Ses créateurs, James K. Baker et son épouse Janet M. Baker, tous deux anciens de Carnegie Mellon, avaient fondé Dragon Systems en 1982. En 2000, l’entreprise est rachetée par Lernout & Hauspie (L&H), fleuron belge de la technologie vocale devenu mondialement célèbre, mais dont l’histoire s’est achevée dans un retentissant scandale financier.
Les actifs de L&H ont ensuite été repris par ScanSoft, qui fusionne en 2005 avec Nuance Communications. Nuance devient alors le leader mondial de la reconnaissance vocale… jusqu’à son rachat par Microsoft en 2022. Aujourd’hui, les héritages de Dragon se retrouvent dans les services cloud récents de Microsoft : Azure, Microsoft 365, Copilot, etc.
Le cas luxembourgeois
Aucun des outils cités jusqu’à présent ne prend en charge le luxembourgeois. Pourtant, le pays dispose aujourd’hui de deux systèmes performants de reconnaissance de la parole : schreifmaschinn.lu et Lux-ASR. Fait étonnant : ces applications ont été accessibles au grand public avant les premiers systèmes de synthèse vocale luxembourgeoise, alors que la technologie ASR est encore plus complexe que celle du TTS. En effet, l’entraînement d’un système ASR exige bien plus d’échantillons audio annotés que pour un modèle TTS.
Dans la suite, j’expliquerai les raisons qui ont permis cette avancée et je retracerai l’histoire du développement de ces deux systèmes.
Les bases technologiques modernes :
- 2009 : lancement de Kaldi, un projet open source de l’Université Johns Hopkins (USA), devenu une référence dans la recherche ASR.
- 2019 : Wav2Vec, modèle développé par Meta AI (Facebook Research), entraîné sur des échantillons couvrant 53 langues.
- 2021 : sortie d’une version étendue de Wav2Vec, supportant 128 langues, dont le luxembourgeois.
- 2021 : Coqui-AI développe en parallèle à ses systèmes TTS un modèle ASR nommé Coqui-STT.
- 2022 : OpenAI publie Whisper (septembre), le modèle ASR open source le plus performant à ce jour, réputé pour sa robustesse et sa précision multilingue.
Trois générations au service de la reconnaissance vocale luxembourgeoise
Trois personnes issues de trois générations différentes se sont lancées dans le développement d’applications ASR en luxembourgeois entre fin 2021 et début 2022.
🎓 La génération Z
Le plus jeune, Le Minh Nguyen (génération Z), est un étudiant luxembourgeois en sciences des technologies vocales à l’Université de Groningen (Pays-Bas). Au printemps 2022, il effectue un stage auprès du ZLS (Zenter fir d’Lëtzebuerger Sprooch) et, à l’été, il obtient son master avec distinction cum laude. Son mémoire de fin d’études s’intitulait « Improving Luxembourgish Speech Recognition with Cross-Lingual Speech ».
À partir de l’automne 2022, il perfectionne son modèle avec l’appui de Sven Colette, linguiste informatique, chercheur et consultant en IA, qui avait rejoint le ZLS au début de 2021. Ensemble, ils enrichissent l’entraînement du modèle ASR avec des échantillons audio/texte supplémentaires fournis par RTL et la Chambre des Députés.
Le volume, la richesse et la qualité de ces enregistrements, associés aux textes sources de RTL et aux transcriptions du secrétariat de la Chambre, ont largement contribué au succès du projet.
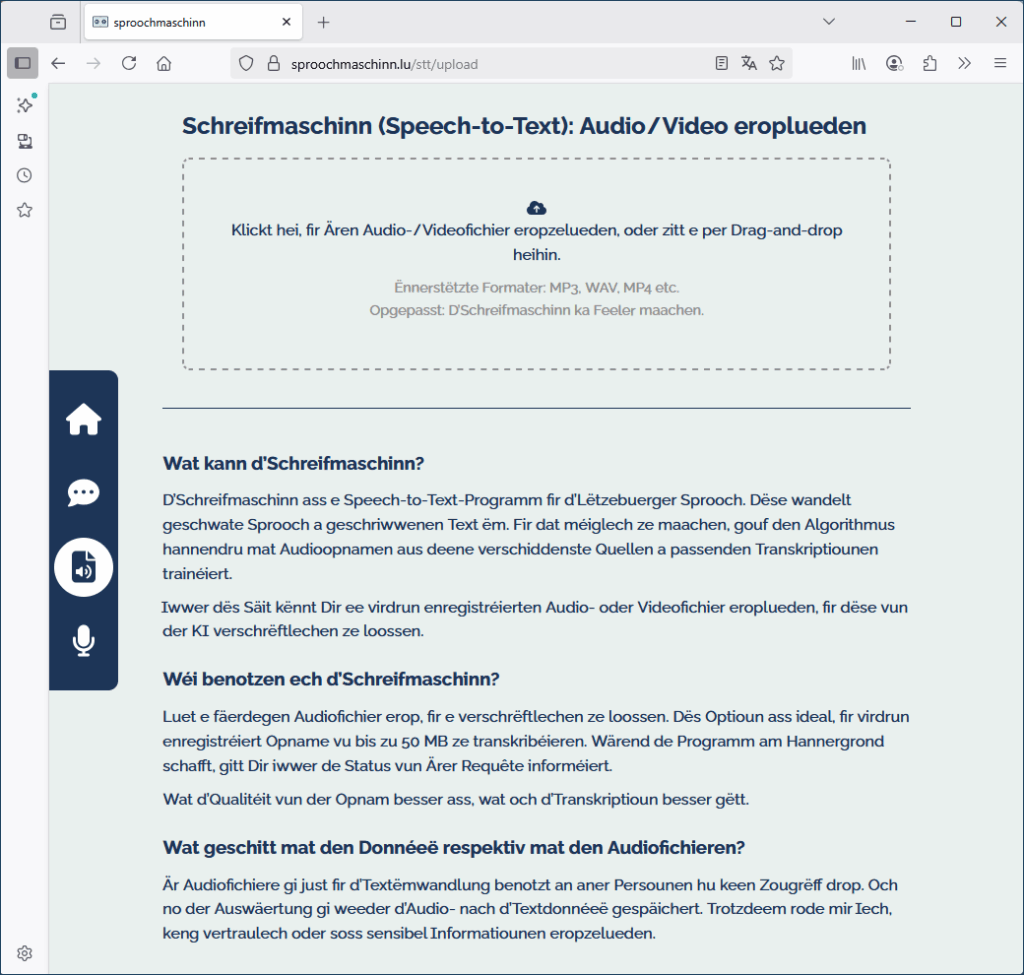
L’application schreifmaschinn.lu est inaugurée le 9 décembre 2022 par Claude Meisch, ministre de l’Éducation nationale et ministre de tutelle du ZLS. Une deuxième version, basée sur le modèle Whisper d’OpenAI, est mise en production fin septembre 2023.
👨🏫 La génération X
Le deuxième acteur est Peter Gilles (génération X), déjà présenté dans un chapitre précédent. Dès février 2022, il publie un premier prototype ASR sur la plateforme HuggingFace, basé sur le modèle Wav2Vec de Meta AI et entraîné sur des données similaires à celles utilisées par le ZLS. En mai 2022, il présente les résultats complets sur le site de l’Université du Luxembourg, sous le titre « A very first model ». Ce fut un jalon important dans le développement des technologies vocales au Luxembourg.
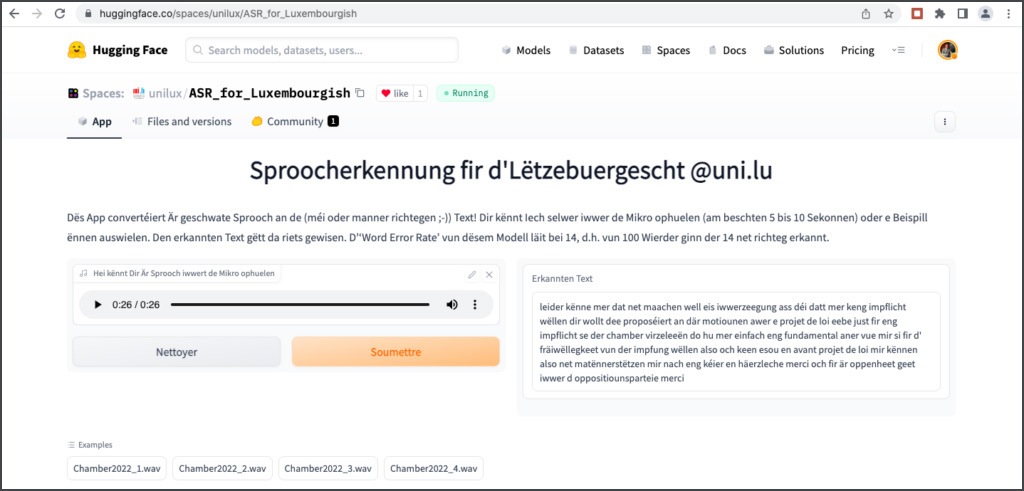
Lors de l’inauguration de schreifmaschinn.lu, Peter Gilles me confie qu’il s’est lancé dans le perfectionnement de Whisper, déjà pré-entraîné pour le luxembourgeois. Quelques mois plus tard, je découvre son premier prototype sur HuggingFace. Mes tests montrent rapidement des performances extraordinaires.
Par la suite, le projet est présenté lors de conférences internationales par Peter Gilles, Nina Hosseini Kivanani et Léopold Edem Ayité Hillah, avant d’être mis à disposition du public sous le nom de Lux-ASR.
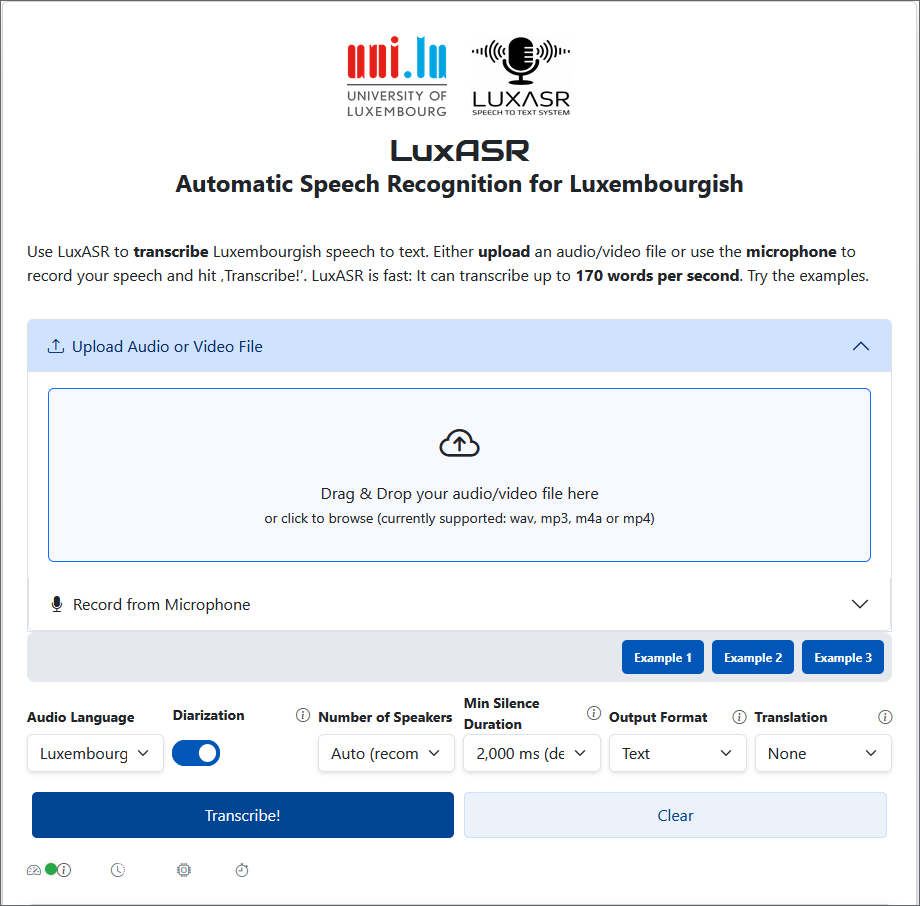
Début 2024, l’Université du Luxembourg et la Chambre des Députés annoncent une phase de test pour assister le secrétariat dans la transcription des débats et discours parlementaires.
Récemment, une API a été mise à disposition des entreprises pour connecter LuxASR à leurs systèmes informatiques. De plus, des applications mobiles pour iOS et Android ont été publiées dans l’App-Store et dans Google Play-Store, permettant d’utiliser LuxASR directement sur smartphone.
Ces outils ne se limitent pas à la reconnaissance du luxembourgeois : ils gèrent également d’autres langues, traduisent les transcriptions, distinguent les voix de différents interlocuteurs et peuvent traiter des vidéos entières afin d’extraire les dialogues et générer des sous-titres. Autant de fonctionnalités qui ouvrent la voie à une véritable machine IA rédactrice de comptes rendus. Nous reviendrons sur ce point dans un prochain chapitre.
👴 La génération baby-boomer
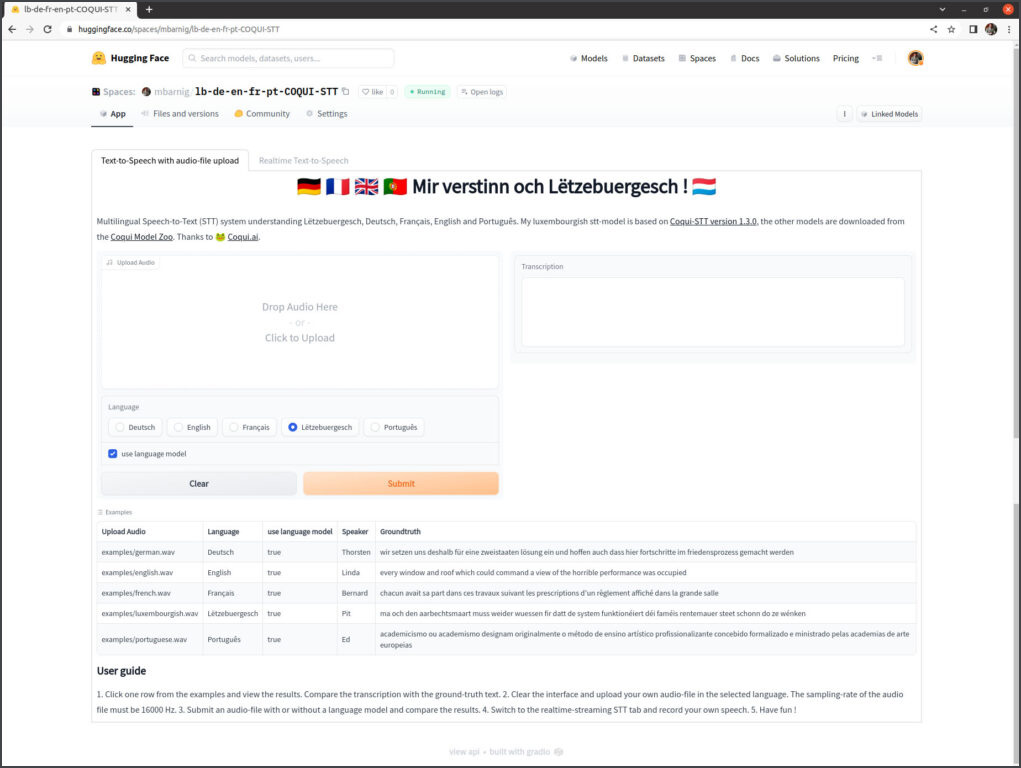
Enfin, j’étais la troisième personne, représentant la génération baby-boomer, également fasciné par l’ASR. Mes premiers développements se sont appuyés sur le modèle Coqui-STT. Fin juillet 2022, j’ai publié sur HuggingFace un modèle STT multilingue intitulé : « Mir verstinn och Lëtzebuergesch ». Mais très vite, j’ai dû reconnaître que face à la supériorité du modèle Whisper, mon projet ne pouvait pas rivaliser. J’ai donc décidé d’arrêter son développement.