Les machines qui parlent notre langue
Pour s’entretenir avec une machine en langage naturel, il faut qu’elle puisse répondre par la voix. La technologie qui rend cela possible est la synthèse vocale, connue sous le sigle TTS (Text-to-Speech).
J’ai toujours été fasciné par cette technologie. En 1976, j’ai supervisé un travail de diplôme à l’Institut d’Électronique de l’EPFZ, réalisé par Kurt Mühlemann. L’objectif était de créer un circuit de synthèse vocale avec des filtres réglés. À la fin, le synthétiseur était capable de prononcer la phrase « Ich bin ein Computer », avec une tonalité résolument robotique.
En 2020, j’ai publié un livre retraçant l’histoire de la synthèse vocale mécanique, électrique, électronique et informatique, sous le titre Synthèse de la Parole.
On y trouve, entre autres, Pedro the Voder, présenté à l’Exposition universelle de New York en 1939, l’Orator Verbis Electris (OVE-1, 1953), le synthétiseur Parametric Artificial Talker (P.A.T., 1958), le Votrax (1970), le célèbre jouet éducatif Speak & Spell (1976), les programmes KlatTalk et DECTalk (1982), ainsi que les systèmes Festival et Merlin, apparus à partir de 1984.
Ces projets, ainsi que leurs inventeurs et inventrices, seront présentés en détail dans un chapitre spécifique.
Aujourd’hui, les sociétés GAFAM (Google, Apple, Facebook, Amazon, Microsoft) proposent des services de synthèse vocale dans le cloud avec des voix artificielles d’une telle qualité qu’il est souvent impossible de les distinguer d’une voix humaine. Hélas, la langue luxembourgeoise n’est pas encore prise en charge par ces grands acteurs.
Les premiers pas au Luxembourg
En mars 2014, j’ai commencé à développer un module de synthèse vocale luxembourgeoise pour la version 1.48.4 du logiciel libre eSpeak. Ce projet avait été lancé en 1995 par Jonathan Duddington, jeune informaticien anglais, pour les ordinateurs personnels ACORN équipés du système d’exploitation RISC OS. Le système utilisait la méthode de synthèse par formants et reposait sur les phonèmes, c’est-à-dire les plus petits sons d’une langue qui permettent de distinguer les mots. On distingue notamment voyelles et consonnes, prononciation voisée (sonore) ou sourde.
1995 était également l’année de lancement d’un projet majeur de synthèse vocale à la Faculté polytechnique de Mons (Belgique). Il s’agissait d’un projet de recherche européen, financé par la Commission européenne et dirigé par Thierry Dutoit.
La méthode retenue reposait sur la concaténation de diphones — des segments de parole qui couvrent la transition entre deux phonèmes. Le système fut baptisé MBROLA, acronyme de Multi-Band Resynthesis OverLap-Add. Cette approche constituait une variante optimisée de la technique PSOLA (Pitch-Synchronous Overlap-Add), spécifiquement adaptée à la synthèse vocale par diphones.
MBROLA n’intégrait pas directement la conversion de texte en phonèmes : cette étape était généralement assurée par des outils complémentaires comme eSpeak. Le projet avait toutefois une particularité novatrice pour l’époque : sa distribution gratuite était autorisée pour des usages non commerciaux, notamment en recherche et en éducation, ce qui a largement contribué à sa diffusion et à son succès académique.
J’avais interrompu mon travail sur eSpeak quand le projet plus avancé MaryLUX a été présenté en septembre 2015 à l’Université du Luxembourg par Ingmar Steiner, Jürgen Trouvain, Judith Manzoni et Peter Gilles. Ce système reposait sur MaryTTS, une technologie de synthèse vocale par sélection d’unités développée à l’Université de la Sarre dès les années 2000.
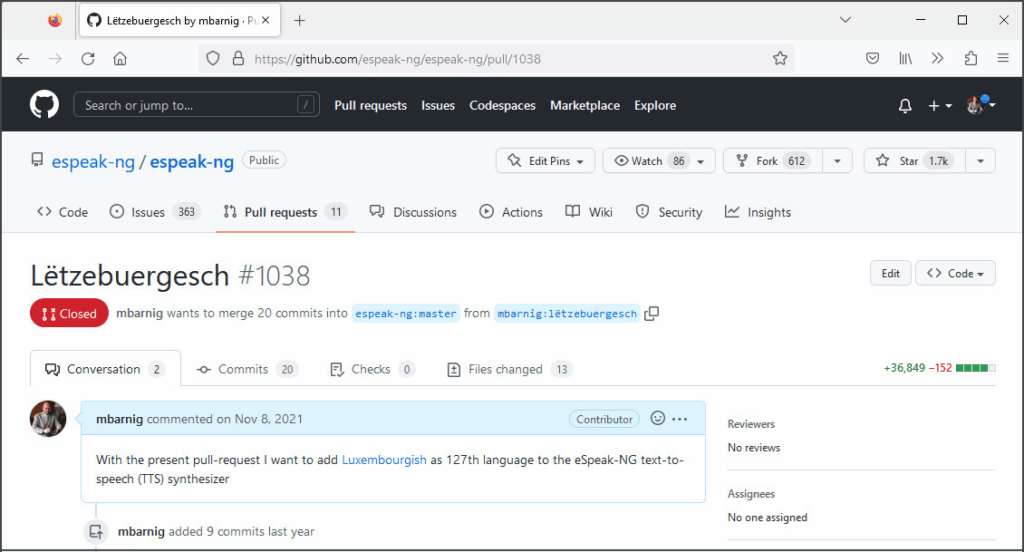
En septembre 2021, j’ai repris le développement du module luxembourgeois pour eSpeak, à la demande d’une personne aveugle qui souhaitait l’utiliser comme lecteur d’écran. C’était alors le seul moyen d’ajouter le luxembourgeois dans l’application libre NVDA (Non Visual Desktop Access), destinée aux aveugles et malvoyants. Le 11 novembre 2021, le luxembourgeois figurait comme 127e langue dans eSpeak-NG (nouvelle génération).
L’apport de Coqui-AI
L’année 2021 fut aussi marquée par la fondation de la start-up allemande Coqui-AI, qui ambitionnait de créer un écosystème européen dédié aux voix synthétiques. L’entreprise proposait une large gamme de modèles TTS basés sur des réseaux neuronaux modernes, accompagnés d’instructions détaillées pour les installer et les exécuter sur des ordinateurs personnels.
Pour la première fois, la communauté mondiale des passionnés de TTS disposait d’un environnement complet pour se familiariser avec l’apprentissage profond, aujourd’hui méthode de référence pour la création de systèmes d’IA vocale. J’ai été un des utilisateurs de la première heure et, sans surprise, j’ai commencé mes essais par la création d’une voix synthétique luxembourgeoise.
Cet exemple est idéal pour expliquer quelles sont les données, compétences et infrastructures nécessaires pour développer une application d’IA. J’en présente ici les grandes lignes avant d’entrer dans les détails dans les chapitres suivants.
Les ingrédients d’un modèle TTS
Le modèle TTS
La condition de départ est la disponibilité d’un modèle performant. Je ne détaillerai pas ici l’installation technique sur un ordinateur ou dans le cloud — c’est déjà une prouesse en soi — mais il faut savoir que le code est généralement partagé sur une plateforme de collaboration comme GitHub.
Les données
Un échantillon est constitué d’un enregistrement audio d’un texte parlé (de quelques secondes à une minute), accompagné d’un fichier texte avec la transcription et la séquence de phonèmes.
Les enregistrements doivent idéalement être réalisés par un locuteur qualifié, dans un studio sans bruit de fond. Mais un seul échantillon ne suffit pas: il en faut des milliers pour entraîner un modèle. Dans une langue dite à faibles ressources comme le luxembourgeois, cela constitue un vrai défi. Les bases de données peuvent être hébergées sur la plateforme HuggingFace, ou sur le portail national data.public.lu s’il s’agit de données luxembourgeoises.
L’entraînement
Avant de lancer l’apprentissage, il faut paramétrer le modèle : nombre d’itérations, format audio, taille des échantillons, etc. Le processus d’entraînement peut durer des heures, des jours, voire des semaines, selon la puissance de calcul disponible et le nombre d’échantillons. L’entraîneur doit analyser régulièrement les logs d’entraînement et réagir aux éventuelles erreurs. En général, cette étape demande une expertise avancée, souvent de niveau doctorat.
La mise au point
Une fois le modèle entraîné, il faut le mettre en production pour les utilisateurs, avec un guide d’usage et un dictionnaire des noms propres, mots étrangers et abréviations. Cette phase de finition requiert elle aussi des compétences spécialisées.
Les premiers modèles luxembourgeois
Pour entraîner mon premier modèle AI-TTS luxembourgeois fin 2021, j’ai utilisé la base de données MaryLUX. Pour le deuxième, j’ai ajouté des dictées disponibles sur le site de l’Université du Luxembourg, avec le consentement des trois oratrices et de Peter Gilles, linguiste et directeur du département des sciences humaines. J’ai publié les résultats sur mon site web le 6 janvier 2022.
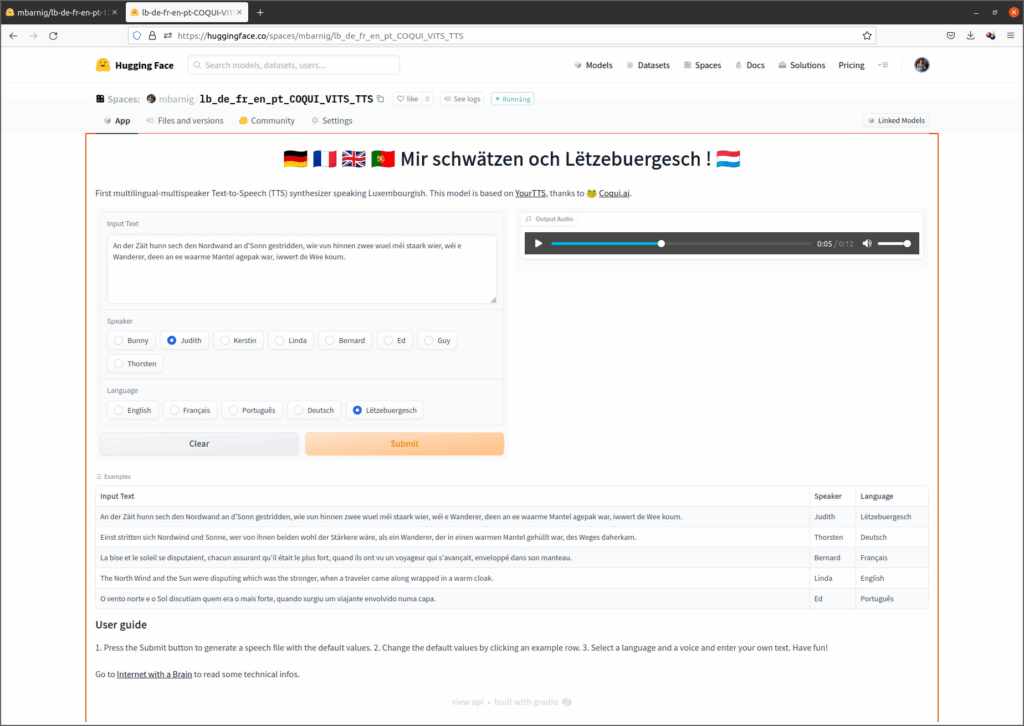
Comme la qualité restait en deçà de l’état de l’art, j’ai enrichi la base avec des échantillons multilingues équilibrés (anglais, français, allemand, portugais) disponibles dans le domaine public, ce qui a permis de multiplier par cinq le volume d’entraînement. Le résultat fut un des premiers modèles TTS multilingues, présenté sur HuggingFace, et salué par la communauté comme par les responsables de Coqui-AI. Chaque voix pouvait synthétiser un texte dans les cinq langues, tout en conservant le charme de son accent natif.
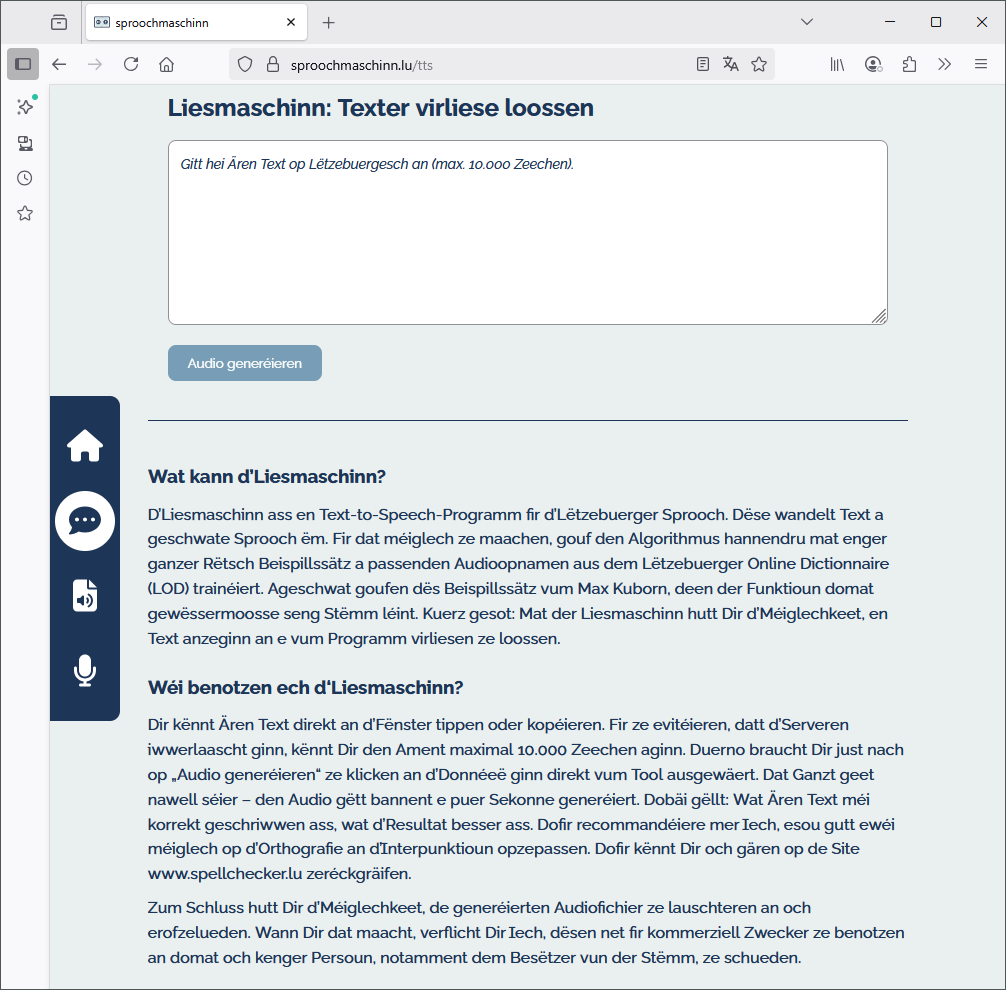
Liesmaschinn.lu
Depuis 2021, je collabore avec le Zenter fir d’Lëtzebuerger Sprooch (ZLS). J’y ai appris que Max Kuborn, collaborateur de longue date de RTL, enregistrait des phrases en luxembourgeois pour documenter la prononciation des mots du LOD (Lëtzebuerger Online Dictionnaire). Convaincu de la valeur de ces données, j’ai demandé à obtenir une copie.
Je pariais que, vu la taille considérable de la base de données, il serait possible de se passer de l’étape intermédiaire des phonèmes et d’entraîner directement le modèle TTS à partir des caractères alphabétiques. Autrement dit, au lieu d’utiliser une première application d’IA pour convertir le texte en phonèmes, puis une deuxième pour transformer ces phonèmes en sons, on pourrait imaginer un modèle capable d’apprendre directement la correspondance lettres → sons grâce à la masse de données disponibles.
En mars 2024, j’ai reçu un premier lot de fichiers. En juillet 2024, j’ai pu présenter une première version du modèle TTS, entraîné avec ces enregistrements, aux responsables du ZLS et au commissaire à la langue luxembourgeoise, Pierre Reding. Tous furent impressionnés par la qualité de la voix synthétisée. On décida alors de mettre le système à disposition du public sous le nom de Schwätzmaschinn.
La responsabilité technique fut ensuite confiée à Christopher Morse, nouveau collaborateur du ZLS, spécialisé dans les technologies IA, qui adapta le modèle pour la production. Après quelques mois, le TTS fut installé sur les ordinateurs du gouvernement, aux côtés du système de reconnaissance vocale schreifmaschinn.lu (ASR), inauguré le 9 décembre 2022. Le projet prit finalement le nom Liesmaschinn.lu, intégré dans le portail combiné Sproochmaschinn.lu.
Le 10 février 2025, le ministre de la Culture, Eric Thill, a présenté officiellement cette plateforme vocale à la presse.
Les évolutions récentes
L’évolution exponentielle de l’IA fait que les grandes étapes se comptent désormais en mois plutôt qu’en années.
- Décembre 2023 : Coqui-AI annonce sa fermeture et ses services disparaissent progressivement.
- Mars 2025 : le gouvernement lance un appel d’offres pour le projet ScreenReaderLB, destiné à remplacer le module eSpeak-NG luxembourgeois dans les lecteurs d’écran pour malvoyants.
- 15 avril 2025 : RTL et l’Université du Luxembourg annoncent le lancement de LuxVoice, un projet de recherche financé par le Fonds National de la Recherche (FNR). L’objectif est de développer un système de synthèse vocale luxembourgeois à la fois expressif sur le plan émotionnel et riche sur le plan linguistique. Les responsables du projet sont :
- Nina Hossemi-Kivanani, cheffe de projet chez RTL
- Tom Weber, CTO de RTL
- Peter Gilles, conseiller scientifique à l’Université du Luxembourg
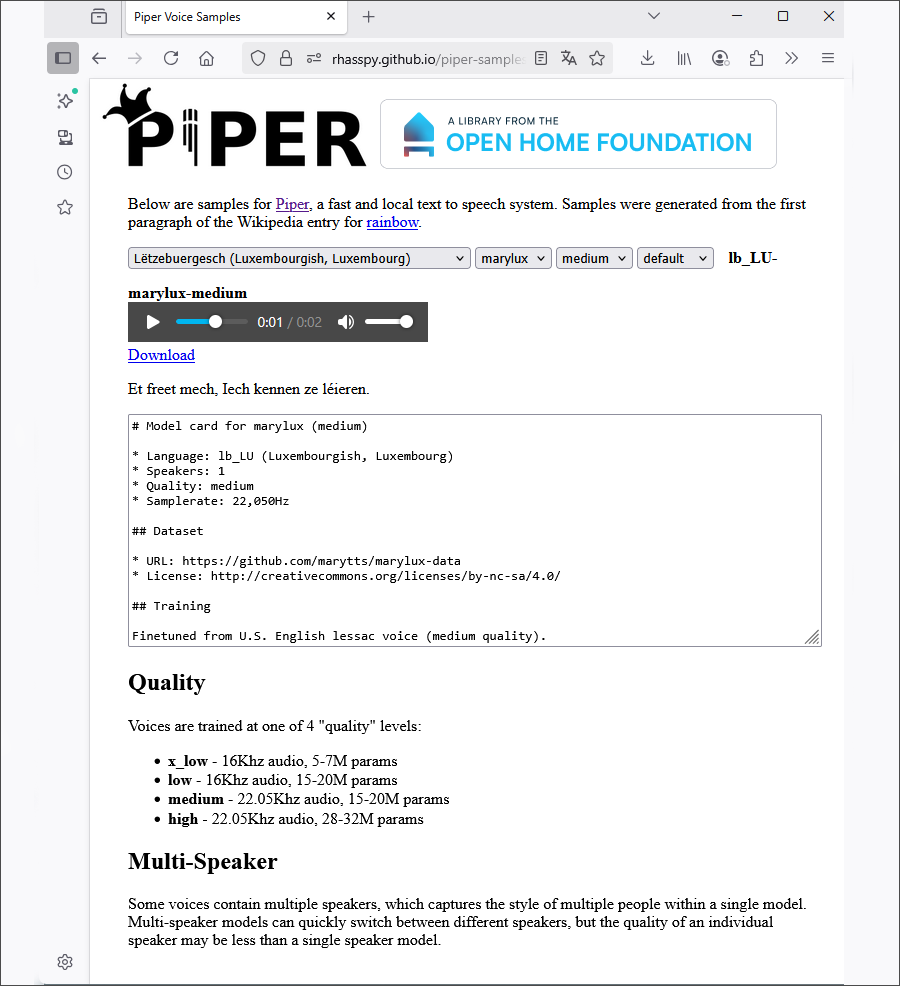
- Mai 2025 : Michel Hansen (alias Synesthesiam), ancien contributeur au projet Coqui-TTS, publie une nouvelle version de son modèle luxembourgeois Piper TTS.
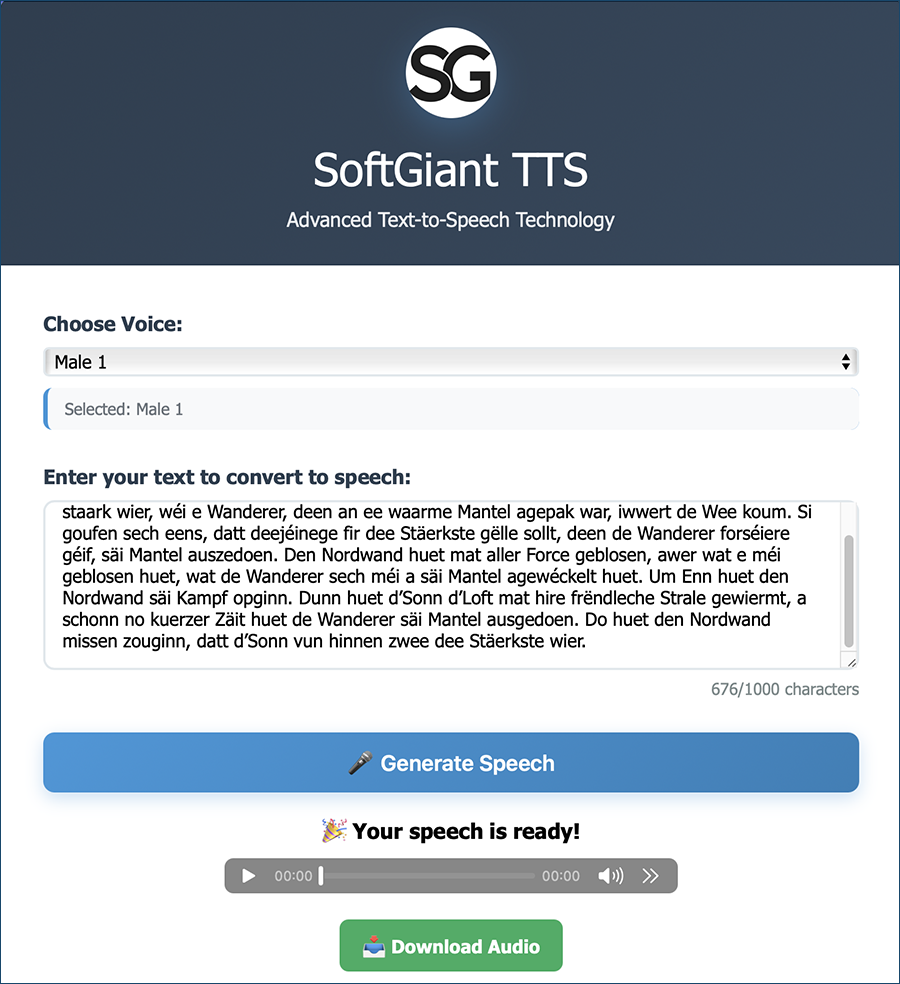
- Juin 2025 : la start-up luxembourgeoise SoftGiant TTS présente son premier modèle luxembourgeois. Malheureusement, la licence de la base du ZLS utilisée pour l’entraînement ne permet pas une exploitation commerciale.